From Chatbots to Agents: Building Production-Ready AI Systems on AWS in 2026
Here's an uncomfortable truth: most AI projects never make it past the demo stage. According to recent research from Recon Analytics, only 8.6% of enterprises h...
Here's an uncomfortable truth: most AI projects never make it past the demo stage.
According to recent research from Recon Analytics, only 8.6% of enterprises have AI agents deployed in production. That's not a typo. Nearly two-thirds of organisations have no formalised AI initiative at all, and most of the rest are stuck in what the industry has started calling "pilot purgatory" – endless experiments that never quite justify the investment.
We've seen this pattern dozens of times at Jelifish. A UK enterprise builds a clever chatbot prototype. Leadership gets excited. Then months pass, and the project sits in limbo – too promising to kill, too risky to deploy.
The gap between a working demo and a production system isn't about intelligence or capability. It's about architecture.
This post is the playbook we wish we'd had when we started building AI agents for UK enterprises. We'll cover the decisions that actually matter: when to use AWS Bedrock versus self-hosting, how to architect Lambda-based agents that scale, why DynamoDB is your secret weapon for state management, and where most teams burn money on LLM costs without realising it.

WHY 2026 CHANGES EVERYTHING
The AI agent market isn't just growing – it's fundamentally shifting. Gartner predicts that 40% of enterprise applications will feature task-specific AI agents by the end of 2026, up from less than 5% in 2025. That's not incremental growth; it's a wholesale architectural transformation.
But here's what the hype cycle misses: the organisations seeing real results aren't the ones with the most sophisticated models. They're the ones who've figured out how to move from experimentation to repeatable, production-grade deployment.
McKinsey's latest State of AI report puts this in stark relief. Twenty-three percent of respondents report their organisations are scaling agentic AI systems somewhere in their enterprises. But most of those scaling agents are only doing so in one or two functions. In any given business function, no more than 10% of organisations are scaling AI agents.
The encouraging signal? The share of organisations with deployed agents nearly doubled in just four months during late 2025. The enterprises investing now are increasingly those with the operational discipline to escape pilot purgatory.
So what separates the 8.6% who've made it to production from everyone else? Let's start with the first decision that trips up most teams.
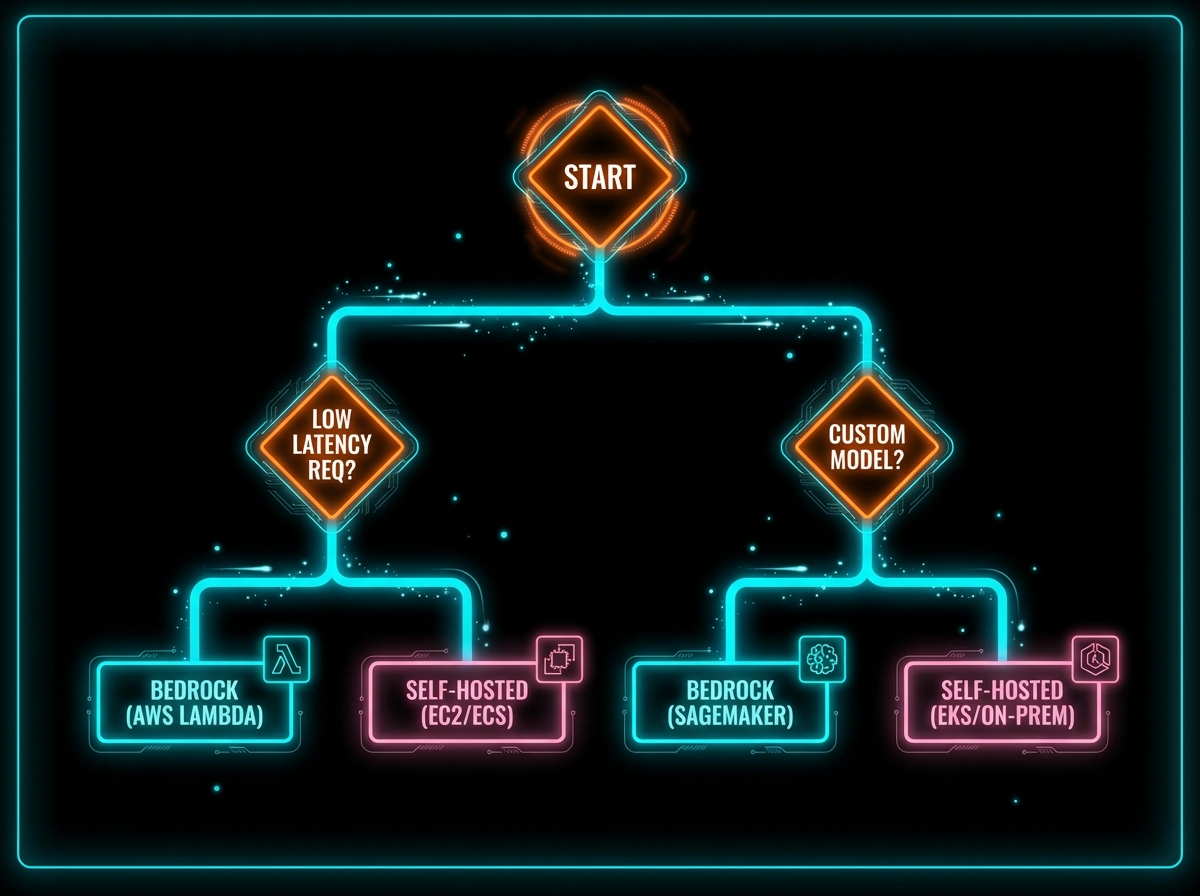
AWS BEDROCK VS SELF-HOSTED: A DECISION FRAMEWORK THAT ACTUALLY WORKS
We get asked this question constantly: "Should we use Bedrock or host our own models?"
The honest answer? It depends on factors most teams haven't thought through properly.
AWS Bedrock gives you access to foundation models from Anthropic, Meta, Mistral, and Amazon's own Nova family through a single API. No infrastructure to manage. No GPUs to provision. You're billed on tokens, which means costs scale linearly with actual usage.
Self-hosting (whether on EC2 or SageMaker) means you control everything: the model weights, the inference stack, the data residency. You pay for compute whether you use it or not, but at scale, the unit economics can work in your favour.

THE FRAMEWORK
Choose Bedrock when: You're moving fast, traffic is unpredictable, you need access to frontier models like Claude, or compliance requirements are met by AWS's security perimeter. Most UK enterprises starting their agent journey should default here.
Consider self-hosting when: You have consistent, high-volume workloads where token costs exceed compute costs. You need fine-tuned models that aren't available through Bedrock. Or you have strict data residency requirements that preclude managed services.
The hybrid approach we often recommend: Use Bedrock for development and low-volume production, with a migration path to SageMaker endpoints once you've validated usage patterns and can justify dedicated capacity.
LAMBDA-BASED AGENT ARCHITECTURE: PATTERNS THAT SCALE
Here's something that surprised us when we started building production agents: the serverless model works brilliantly for agentic AI, but not in the way most tutorials suggest.
AWS's Strands Agents SDK is compute-agnostic – the agents you build are standard Python applications that can run anywhere. But for most UK enterprise workloads, Lambda-based deployment hits the sweet spot between cost, scalability, and operational simplicity.
THE ARCHITECTURE WE DEPLOY
A typical production agent at Jelifish follows this pattern:
API Gateway handles incoming requests with JWT verification offloaded to the ALB. This isn't just about security – it significantly reduces the complexity you need to manage in your application code.
Lambda functions execute the agent logic. Each function handles a specific tool or capability. The key insight: separate your agent's core reasoning from the interface layer. This lets you reuse the same agent code whether you're invoking through API Gateway, processing SQS messages, or running in Bedrock AgentCore Runtime.
Bedrock AgentCore (now GA) orchestrates the reasoning loop. The AgentCore Gateway provides a secure interface for tool calls, while AgentCore Memory handles both session state and long-term context. This is genuinely game-changing for production deployments – AWS manages the operational complexity of scaling, monitoring, and infrastructure.
EventBridge acts as the central nervous system, routing agent state changes and task completions. We've found this event-driven approach essential for building resilient agents that can recover from failures and handle long-running workflows.
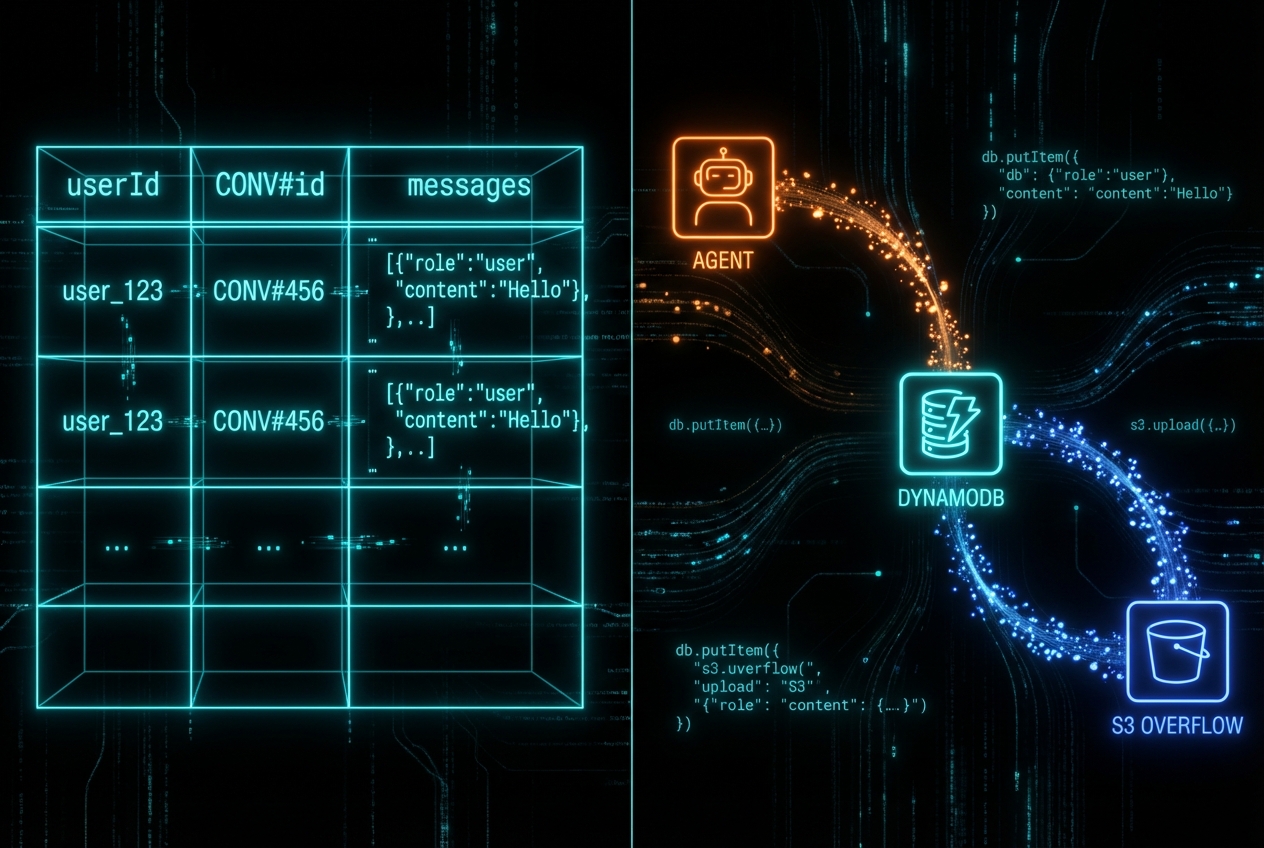
DYNAMODB FOR AGENT STATE MANAGEMENT: THE PATTERN EVERYONE MISSES
An agent is only as good as its memory. And here's where most implementations fall apart.
Early AI assistants were stateless – each prompt processed in isolation, with no memory of prior interactions. Modern agents need to maintain context across conversations, remember user preferences, track multi-step workflows, and recover gracefully from failures.
DynamoDB turns out to be remarkably well-suited for this. But the pattern that works isn't obvious.
COST OPTIMISATION FOR LLM WORKLOADS: WHERE TEAMS ACTUALLY BURN MONEY
Let's talk about the uncomfortable topic: LLM costs can spiral out of control faster than any other cloud expense you've managed.
A single customer support agent handling 2 million questions per month can cost tens of thousands in inference alone – before you factor in guardrails, embeddings, and vector storage. We've seen UK enterprises blow their entire quarterly AI budget in weeks because nobody modelled the costs properly.

PRODUCTION READINESS CHECKLIST: WHAT ACTUALLY MATTERS
Before you deploy anything to production, work through this checklist. We've learned most of these the hard way.
Retry logic with exponential backoff – LLM APIs fail. Rate limits get hit. Your agent needs to handle this gracefully, not crash.
Dead-letter queues for async workflows – When processing fails, you need a way to inspect and replay failures without losing data.
Circuit breakers for external tool calls – If a tool is failing, stop calling it rather than burning tokens on doomed requests.
WHAT WE'VE LEARNED BUILDING AGENTS FOR UK ENTERPRISES
After deploying AI agents across financial services, retail, and professional services in the UK, a few patterns keep emerging.
Start smaller than you think. The most successful deployments we've seen started with a narrow, well-defined use case – not a general-purpose assistant. Get one thing working in production, learn from it, then expand.
Data quality trumps model capability. We've seen simple RAG implementations outperform complex agent architectures because the underlying data was clean, well-structured, and properly chunked. Don't blame the model when your data is the problem.
Latency matters more than accuracy past a certain point. Users will tolerate a slightly less precise answer if it arrives in 2 seconds instead of 10. Design for responsiveness, not just correctness.
The 8.6% who've made it to production aren't smarter – they're more disciplined. They've accepted that production AI requires production engineering. No shortcuts.
Need help with your project?
Our team specializes in cloud architecture, serverless solutions, and modern application development.
Contact Us